Particionamento no BigQuery: O Guia Prático que Vai Reduzir Seus Custos
Entenda como o BigQuery cobra por dados processados, os 3 tipos de particionamento disponíveis e como aplicar em tabelas novas e existentes — com código completo.
No último post, mostrei como reduzi 90% dos custos de BigQuery de um cliente. Particionamento foi a mudança principal. Hoje vou mostrar como implementar.
Se você leu o post anterior, viu que 14 tabelas sem partição estavam gerando R$ 13.500/mês de custo desnecessário. A correção mais impactante foi aplicar particionamento nessas tabelas — o custo por query caiu de R$ 1,25 para R$ 0,01.
Mas o que exatamente é particionamento? Como funciona por baixo dos panos? E como aplicar em tabelas que já existem em produção com dados históricos?
Este post responde essas três perguntas com código completo.
Por que o BigQuery cobra tanto sem partição
O BigQuery tem um modelo de cobrança diferente de bancos de dados tradicionais. Ele não cobra por tempo de processamento ou por linhas retornadas — ele cobra por volume de dados lidos.
Quando você executa uma query, o BigQuery precisa ler os dados do storage. Se a tabela não tem partição, ele lê a tabela inteira, mesmo que sua query tenha um WHERE filtrando por data. O filtro é aplicado depois da leitura, não antes.
Para visualizar o impacto:
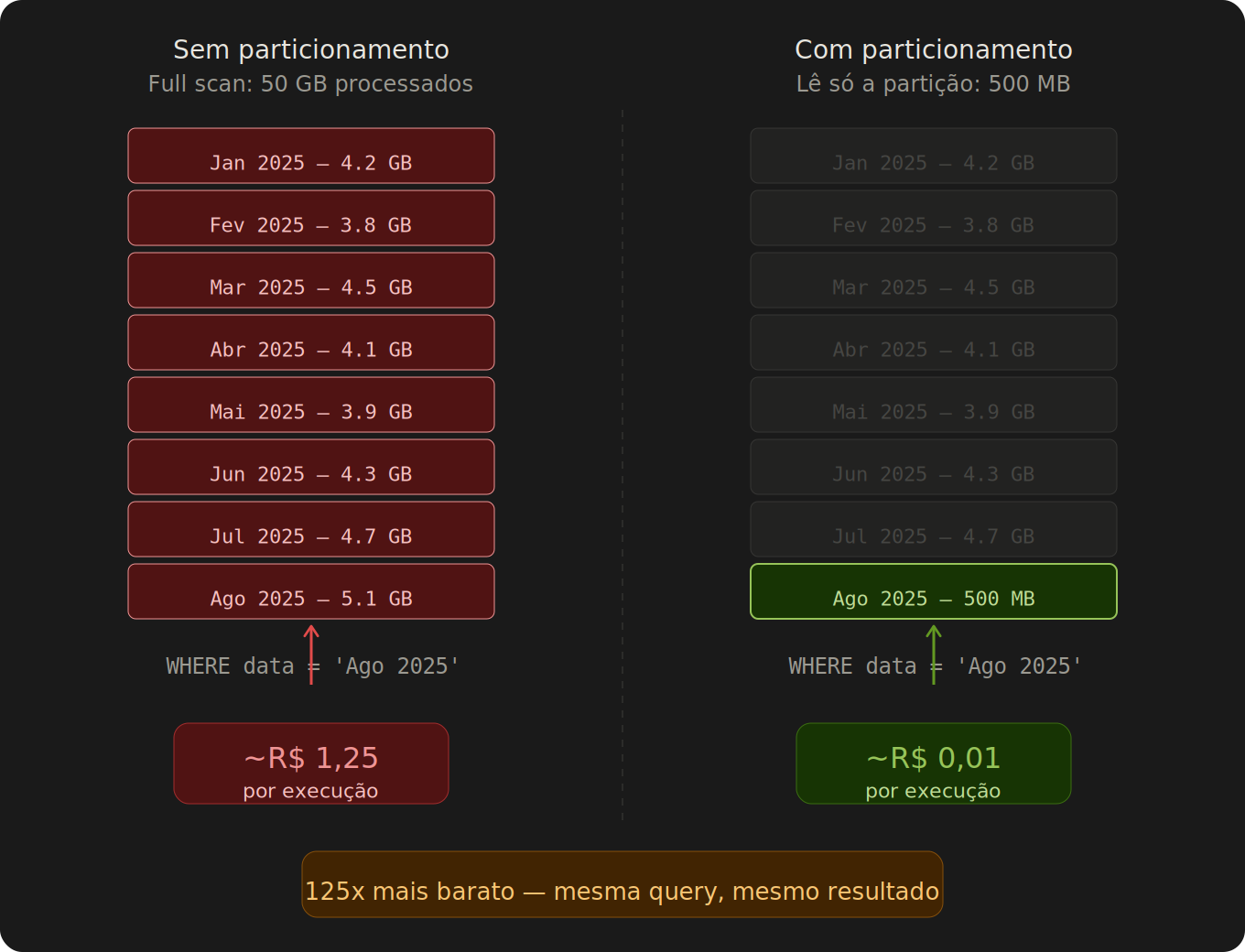
Na prática, a mesma query com o mesmo resultado custa 125x menos com particionamento. E quanto maior a tabela, maior a diferença.
No modelo on-demand do BigQuery, o preço é de US$ 6,25 por TB processado (cerca de R$ 31,25 por TB na cotação atual). Pode parecer pouco, mas multiplique pelo número de queries, tabelas e frequência de execução — e o billing explode.
O particionamento resolve isso na raiz: ele organiza os dados fisicamente em blocos, e o BigQuery lê apenas os blocos relevantes para a query.
Os 3 tipos de particionamento no BigQuery
O BigQuery oferece três formas de particionar uma tabela. Cada uma se aplica a um cenário diferente.
1. Partição por coluna de data (ou timestamp)
O mais comum e o que você vai usar em 90% dos casos. Você escolhe uma coluna de data da sua tabela e o BigQuery cria uma partição por dia (ou mês, ou hora).
Quando você faz SELECT * FROM dataset.vendas WHERE data_venda = '2025-08-20', o BigQuery lê apenas a partição daquele dia. Todo o resto da tabela é ignorado.
Quando usar: sempre que sua tabela tiver uma coluna de data ou timestamp — que é a maioria dos casos em data engineering.
2. Partição por data de ingestão
Quando a tabela não tem uma coluna de data confiável, você pode usar a data em que os dados foram inseridos no BigQuery. O sistema cria automaticamente uma pseudo-coluna chamada _PARTITIONDATE.
Quando usar: quando seus dados chegam de fontes externas sem uma coluna de data padronizada, ou quando a data relevante é a data de chegada, não a data do evento.
3. Partição por integer range
Menos comum, mas útil quando sua tabela não tem data e sim um campo numérico como ID de cliente ou código de região.
Quando usar: tabelas sem dimensão temporal onde as queries frequentemente filtram por um campo numérico específico.
Na prática: como escolher
| Cenário | Tipo de partição | Exemplo |
|---|---|---|
| Tabela com coluna de data/timestamp | Por coluna de data | PARTITION BY DATE(created_at) |
| Dados sem data confiável | Por ingestão | PARTITION BY _PARTITIONDATE |
| Tabela sem data, filtro numérico | Por integer range | PARTITION BY RANGE_BUCKET(region_id, ...) |
Na maioria dos projetos que trabalho, 80-90% das tabelas usam partição por coluna de data. É o padrão. Se você não tem certeza, comece por aí.
Como aplicar em tabelas que já existem
Aqui está o ponto que pega muita gente: o BigQuery não permite alterar o particionamento de uma tabela existente. Não existe ALTER TABLE ... ADD PARTITION BY.
O processo para tabelas existentes com dados em produção é:
- Criar uma nova tabela particionada com os dados da original
- Validar que os dados estão corretos
- Substituir a tabela original
Parece arriscado? É mais simples do que parece. O BigQuery faz tudo em uma operação atômica.
Passo a passo completo
O CREATE TABLE ... PARTITION BY ... AS SELECT * cria a tabela particionada e copia todos os dados em uma única operação. Não precisa criar a tabela vazia e depois fazer INSERT INTO — isso é desnecessário e mais lento.
A validação é essencial. Compare a contagem total e faça um spot check nos dados. Se a tabela tiver colunas calculadas ou views que dependem dela, teste também.
Esse é o padrão correto de migração no BigQuery:
CREATE TABLE ... PARTITION BY ... AS SELECT *— cria a nova tabela com dados- Valida contagem e integridade
ALTER TABLE original RENAME TO backup— preserva a originalALTER TABLE nova RENAME TO original— substitui
Por que manter o backup? Se qualquer coisa der errado — um pipeline que quebrou, uma view que depende de schema específico — você faz o rollback renomeando de volta. Depois de validar por alguns dias, pode dropar o backup com segurança.
Sobre tabelas com schema complexo
Se sua tabela tem colunas STRUCT, ARRAY ou tipos aninhados, o CREATE TABLE ... AS SELECT * preserva tudo. O BigQuery copia o schema completo. A única coisa que muda é a adição do particionamento.
Se a tabela tiver clustering além do particionamento, adicione na criação:
Como verificar que está funcionando
Depois de aplicar o particionamento, tem dois jeitos de confirmar que está fazendo diferença:
1. Estimador de bytes no console
Antes de executar qualquer query no BigQuery Console, ele mostra quantos bytes serão processados no canto superior direito. Compare a mesma query na tabela antiga (backup) e na nova:
2. Query na INFORMATION_SCHEMA
Para verificar o particionamento de todas as tabelas do seu dataset de uma vez:
Use isso como checklist periódica. Toda tabela em produção deveria ter particionamento — se aparecer NONE, é hora de corrigir.
Erros comuns que vejo em projetos
Ao longo de 10 anos trabalhando com dados, esses são os erros mais frequentes que encontro quando o assunto é particionamento:
1. Criar a tabela sem partição e "depois a gente resolve"
Depois nunca chega. E quando chega, a tabela já tem 200 GB e o billing já acumulou milhares de reais. Defina o particionamento na criação da tabela. Sempre.
2. Não filtrar pela coluna de partição nas queries
De nada adianta ter particionamento se as queries não filtram pela coluna particionada. Se sua tabela é particionada por data_venda e você faz SELECT * FROM vendas WHERE produto = 'X' sem filtro de data, o BigQuery faz full scan do mesmo jeito.
3. Tentar alterar partição com ALTER TABLE
O BigQuery não suporta ALTER TABLE para mudar particionamento. Use o padrão de migração que mostrei acima (CREATE AS SELECT → RENAME → RENAME).
4. Partição muito granular
Particionar por hora em uma tabela que recebe 100 registros por dia cria milhares de partições pequenas. O BigQuery tem limite de 4.000 partições por tabela e partições muito pequenas podem até piorar a performance. Na maioria dos casos, partição diária é o ideal.
Checklist: seu BigQuery está otimizado?
Se não marcou todos os itens, tem espaço pra otimizar — e provavelmente dinheiro sendo jogado fora todo mês.
Quer praticar?
Na GC Data Academy, toda semana publicamos um desafio prático de Data Engineering. O primeiro desafio é justamente sobre particionamento no BigQuery — você recebe um cenário real, implementa a solução e recebe feedback detalhado em menos de 5 minutos.
É gratuito. Acesse a plataforma e faça o desafio →
Faça nosso Assessment de Maturidade de Dados — diagnóstico gratuito em 3 minutos com recomendações personalizadas.
Guilherme Colla é Data Engineer com 10 anos de experiência, 3x certificado GCP. Precisa de ajuda para otimizar seus custos de cloud? Entre em contato para uma consultoria personalizada.